
#1. Indications for an Effective Job Search
#2. Best GPT Chat Prompts for HR and Recruiters
#3. Best GPT Chat Prompts for Business Owners to Get Things Done
#4. Best GPT Chat Prompts for Entrepreneurs
Data governance defines roles, responsibilities, and processes to ensure accountability and ownership of data assets across the enterprise.
Data governance is a system for defining who within an organization has authority and control over data assets and how those data assets can be used. It encompasses the people, processes, and technologies needed to manage and protect data assets.
The Data Governance Institute defines it as “a system of decision rights and responsibilities for information-related processes, executed according to agreed models that describe who can take what actions with what information, and when, under what circumstances, using what methods.”
The Data Management Association (DAMA) International defines it as the “planning, monitoring and control over data management and the use of data and data-related sources.”
Data governance can best be thought of as a function that supports an organization’s overall data management strategy. Such a framework provides your organization with a holistic approach to collecting, managing, protecting, and storing data. To help understand what a framework should cover, DAMA envisions data management as a wheel, with the governance of
Data as the hub from which the following 10 data management knowledge areas radiate:
When establishing a strategy, each of the above facets of data collection, management, archiving, and use should be considered.
The Business Application Research Center (BARC) warns that data governance is a highly complex and ongoing program, not a “big bang initiative,” and risks participants losing trust and interest over time. To counter that, BARC recommends starting with a manageable or application-specific prototype project and then expanding across the enterprise based on lessons learned.
BARC recommends the following steps for implementation:
Data governance is only one part of the overall discipline of data management, although it is important. While data governance is about the roles, responsibilities, and processes for ensuring accountability and ownership of data assets, DAMA defines data management as “an umbrella term describing the processes used to plan, specify, enable, create, acquire, maintain, use, archive, retrieve, control, and purge data.”
While data management has become a common term for the discipline, it is sometimes referred to as data resource management or enterprise information management (EIM). Gartner describes EIM as “an integrative discipline for structuring, describing and governing information assets across organizational and technical boundaries to improve efficiency, promote transparency and enable business insight.”
Most companies already have some form of governance in place for individual applications, business units, or functions, even if the processes and
Responsibilities are informal. As a practice, it is about establishing systematic and formal control over these processes and responsibilities. Doing so can help businesses remain responsive, especially as they grow to a size where it’s no longer efficient for people to perform cross-functional tasks. Several of the overall benefits of data management can only be realized after the company has established systematic data governance. Some of these benefits include:
The goal is to establish the methods, set of responsibilities, and processes for standardizing, integrating, protecting, and storing corporate data. According to BARC, the key objectives of an organization should be:
BARC notes that such programs always span the strategic, tactical and operational levels in companies, and should be treated as continuous, iterative processes.
According to the Data Governance Institute, eight principles are at the core of all successful data governance and management programs:
Data governance strategies must adapt to best fit an organization’s processes, needs, and goals. Still, there are six basic best practices worth following:
For more information on how to get data governance right, see “6 Best Practices for Good Data Governance.”
Good data governance is not an easy task. It requires teamwork, investment and resources, as well as planning and monitoring. Some of the main challenges of a data governance program include:
To learn more about these pitfalls and others, see “7 Data Governance Mistakes to Avoid.”
Data governance is an ongoing program rather than a technology solution, but there are tools with data governance features that can help support your program. The tool that suits your business will depend on your needs, data volume, and budget. According to PeerSpot, some of the most popular solutions include:
Data Governance Solution
Colllibra Governance: Collibra is an enterprise-wide solution that automates many governance and administration tasks. It includes a policy manager, a data help desk, a data dictionary, and a business glossary.
SAS Data Management: Built on the SAS platform, SAS Data Management provides a role-based GUI for managing processes and includes an integrated enterprise glossary, SAS and third-party metadata management, and lineage visualization.
Erwin Data Intelligence (DI) for Data Governance: Erwin DI combines data catalog and data literacy capabilities to provide insight and access to available data assets. It provides guidance on the use of those data assets and ensures that data policies and best practices are followed.
Informatica Axon: Informatica Axon is a collection center and data marketplace for support programs. Key features include a collaborative business glossary, the ability to visualize data lineage, and generate data quality measurements based on business definitions.
SAP Data Hub: SAP Data Hub is a data orchestration solution aimed at helping you discover, refine, enrich, and govern all types, varieties, and volumes of data across your data environment. It helps organizations establish security settings and identity control policies for users, groups, and roles, and streamline best practices and processes for security logging and policy management.
Alathion: A business data catalog that automatically indexes data by source. One of its key capabilities, TrustCheck, provides real-time “guardrails” to workflows. Designed specifically to support self-service analytics, TrustCheck attaches guidelines and rules to data assets.
Varonis Data Governance Suite: Varonis’ solution automates data protection and management tasks by leveraging a scalable metadata framework that allows organizations to manage data access, view audit trails of every file and email event, identify data ownership across different business units, and find and classify sensitive data and documents.
IBM Data Governance: IBM Data Governance leverages machine learning to collect and select data assets. The integrated data catalog helps companies find, select, analyze, prepare, and share data.
Data Governance Certifications
Data governance is one system, but there are some certifications that can help your organization gain an edge, including the following:
For related certifications, see “10 Master Data Management Certifications That Will Pay Off.”
Data governance roles
Every company makes up its data governance differently, but there are some commonalities.
Steering Committee: Governance programs are enterprise-wide, usually beginning with a steering committee composed of senior managers, often C-level individuals or vice presidents responsible for lines of business. Morgan Templar, author of Get Governed: Building World Class Data Governance Programs, says steering committee members’ responsibilities include setting the overall governance strategy with specific outcomes, championing the work of data stewards, and holding the governance organization accountable for timelines and results.
Data owner: Templar says data owners are individuals responsible for ensuring that information within a specific data domain is governed across systems and lines of business. They are generally members of the steering committee, although they may not be voting members. Data subjects are responsible for:
Data Administrator: Data stewards are responsible for the day-to-day management of data. They are subject matter experts (SMEs) who understand and communicate the meaning and use of information, Templar says, and work with other data stewards across the organization as the governing body of the organization.
Most data decisions. Data stewards are responsible for:
The explosion of artificial intelligence is making people rethink what makes us unique. Call it the AI effect.
Artificial intelligence has made impressive leaps in the last year. Algorithms are now doing things, like designing drugs, writing wedding vows, negotiating deals, creating artwork, composing music, that have always been the sole prerogative of humans.
There has been a lot of furious speculation about the economic implications of all this. (AI will make us wildly productive! AI will steal our jobs!) However, the advent of sophisticated AI raises another big question that has received far less attention: How does this change our sense of what it means to be human? ? Faced with ever smarter machines, are we still… well, special?
“Humanity has always seen itself as unique in the universe,” says Benoît Monin, a professor of organizational behavior at Stanford Business School. “When the contrast was with animals, we pointed to our use of language, reason, and logic as defining traits. So what happens when the phone in your pocket is suddenly better than you at these things?”
Monin and Erik SantoroOpen in a new window, then a doctoral candidate in social psychology at Stanford, started talking about this a few years ago, when a program called AlphaGo was beating the world’s best players at the complex strategy game Go. What intrigued them was how people reacted to the news.
“We noticed that when discussing these milestones, people often seemed defensive,” says Santoro, who earned his Ph.D. this spring and will soon begin a postdoc at Columbia University. “The talk would gravitate towards what the AI couldn’t do yet, like we wanted to make sure nothing had really changed.”
And with each new breakthrough, Monin adds, came the refrain: “Oh, that’s not real intelligence, that’s just mimicry and pattern matching,” ignoring the fact that humans also learn by imitation, and we have our own share of heuristics. flaws, biases, and shortcuts that fall far short of objective reasoning.
This suggested that if humans felt threatened by new technologies, it was about more than just the safety of their paychecks. Perhaps people were anxious about something more deeply personal: their sense of identity and their relevance in the grand scheme of things.
There is a well-established model in psychology called social identity theory. The idea is that humans identify with a chosen group and define themselves in contrast to outgroups. It is that deeply ingrained us vs. them instinct that drives so much social conflict.
“We thought, maybe AI is a new benchmark group,” Monin says, “especially since it’s portrayed as having human-like traits.” He and Santoro wondered: If people’s sense of uniqueness is threatened, will they try to distinguish themselves from their new rivals by changing their criteria of what it means to be human—in effect, moving the goal posts?
To find out, Santoro and Monin put together a list of 20 human attributes, 10 of which we currently share with AI. The other 10 were traits that they felt were distinctive to humans.
They polled 200 people on how capable they thought humans and AI were at each trait. Respondents rated humans most capable on all 20 traits, but the gap was small on shared traits and quite large on distinctive ones, as expected.
Now for the main test: The researchers divided about 800 people into two groups. Half read an article titled “The Artificial Intelligence Revolution,” while a control group read an article about the remarkable attributes of trees. Then, going back to the list of 20 human attributes, test subjects were asked to rate “how essential” each one is to being human.
Indeed, people reading about AI rated distinctively human attributes like personality, morality, and relationships as more essential than those who read about trees. In the face of advances in AI, people’s sense of human nature has been reduced to emphasize traits that machines do not have. Monin and Santoro called this the AI Effect.
To rule out other explanations, they performed several more experiments. In one, participants were simply told that the AI was getting better. “Same result,” says Monin. “Every time we mentioned advances in AI, we got this increase in the importance of distinctive human attributes.”
Surprisingly, the participants did not downplay traits shared by humans and AI, as the researchers had predicted they would. “So even if humans aren’t the best at logic anymore, they didn’t say that logic is any less central to human nature,” Santoro notes.
Of course, artificial intelligence isn’t exactly like an invading tribe with foreign manners; after all, we created it to be like us. (Neural networks, for example, are inspired by the architecture of the human brain.) But there’s an irony here: the cognitive abilities and ingenuity that made AI possible are now the realm in which machines are outpacing us. And as the present research findings suggest, that may lead us to place more value on other traits.
It’s also worth noting that those cognitive skills still command high status and salary. Could that change if soft skills like warmth and empathy, the ability to nurture growth in others, are valued more? Will lawyers and quants be paid less, while teachers and carers receive more respect and money?
“That’s certainly one possible implication of our work,” Monin says. “There are a lot of skills that will not only not be taken over by AI, but people will increasingly value. In a world of ubiquitous and capable AI, soft skills will likely be increasingly sought after by employers” .
In the meantime, he says to her, the effect of the AI is likely to be growing. “Since we conducted this research, the real world has surpassed anything we could have imagined. There has been a constant barrage of information about new achievements in AI. So everything we saw in our little version in the lab is probably already happening to a much broader scale in society.

Machine learning (ML) and artificial intelligence (AI) have received a lot of public interest in recent years, and both terms are practically commonplace in IT parlance. Despite their similarities, there are some important differences between ML and AI that are often neglected.
Therefore, we will cover the key differences between ML and AI in this blog so that you can understand how these two technologies vary and how they can be used together.
Let’s get started!
Understanding Machine Learning (ML)
Machine learning (ML) is a subfield of artificial intelligence (AI) that automates the analysis and prediction of data using algorithms and statistical models. It allows systems to recognize patterns and correlations in large amounts of data and can be applied to a variety of applications such as image recognition, natural language processing, and others.
ML is fundamentally about learning from data. It is a continuous method of developing algorithms that can learn from past data and predict future data. In this approach, ML algorithms can continually improve their performance over time by discovering previously unknown or undetectable patterns.
Types of Machine Learning Algorithms
There are commonly 4 types of machine learning algorithms. Let’s get to know each one of them.
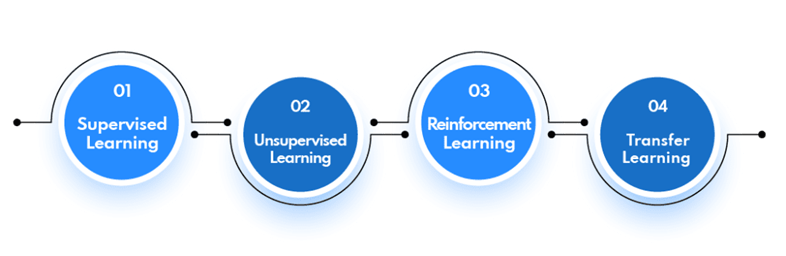
1. Supervised learning
Supervised learning includes providing the ML system with labeled data, which helps it understand how unique variables connect to each other. When presented with new data points, the system applies this knowledge to make predictions and decisions.
2. Unsupervised learning
Unlike supervised learning, unsupervised learning does not require labeled data and uses various clustering methods to detect patterns in large amounts of unlabeled data.
3. Reinforcement learning
Reinforcement learning involves training an agent to act in a specific context by rewarding or punishing it for its actions.
4. Transfer learning
Transfer learning includes using knowledge from previous activities to learn new skills efficiently.
Now, for more understanding, let’s explore some machine learning examples.
Machine Learning Examples
Let’s understand machine learning more clearly through real life examples.
1. Image Recognition: Machine learning is applied to photos and videos to recognize objects, people, landmarks, and other visual elements. Google Photos uses ML to understand faces, locations, and other elements in images so they can be conveniently searched and categorized.
2. Natural Language Processing (NLP): NLP allows machines to interpret language as humans do. Automated customer service chatbots, for example, use ML algorithms to reliably answer queries by understanding text and recognizing the purpose behind it.
3. Speech Recognition: ML is used to allow computers to understand speech patterns. This technology is used for voice recognition applications such as Amazon’s Alexa or Apple’s Siri.
4. Recommendation Engines: Machine learning algorithms identify patterns in data and make suggestions based on those patterns. Netflix, for example, applies machine learning algorithms to suggest movies or TV shows to viewers.
5. Self-driving cars: Machine learning is at the heart of self-driving cars. It is used for object detection and navigation, allowing cars to identify and navigate around obstacles in their environment.
Now, we hope you get a clear understanding of machine learning. Now is the perfect time to explore Artificial Intelligence (AI). So, without further ado, let’s dive into the AI.
Understanding artificial intelligence (AI)
Artificial intelligence (AI) is a type of technology that attempts to replicate the capabilities of human intelligence, such as problem solving, decision making, and pattern recognition. In anticipation of changing circumstances and new insights, AI systems are designed to learn, reason, and self-correct.
Algorithms in AI systems use data sets to obtain information, solve problems, and develop decision-making strategies. This information can come from a wide range of sources, including sensors, cameras, and user feedback.
Algorithms in AI systems use data sets to obtain information, solve problems, and develop decision-making strategies. This information can come from a wide range of sources, including sensors, cameras, and user feedback.
AI has been around for several decades and has grown in sophistication over time. It is used in various industries including banking, healthcare, manufacturing, retail, and even entertainment. AI is rapidly transforming the way businesses operate and interact with customers, making it an indispensable tool for many companies.
In the modern world, AI has become more common than ever. Businesses are turning to AI-powered technologies such as facial recognition, natural language processing (NLP), virtual assistants, and autonomous vehicles to automate processes and reduce costs.
Ultimately, AI has the potential to revolutionize many aspects of everyday life by providing people with more efficient and effective solutions. As AI continues to evolve, it promises to be an invaluable tool for companies looking to increase their competitive advantage.
We have many examples of AI associated with our daily lives. Let’s explore some of them:
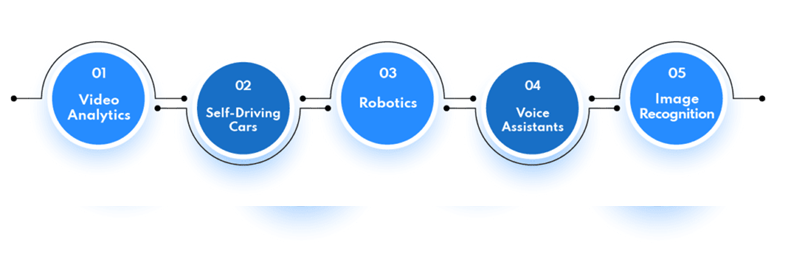
AI Examples
Some of the real life use cases of Artificial Intelligence are:
1. Video Analytics: Video Analytics is an AI application that analyzes video streams and extracts valuable data from them using computer vision algorithms. It can be used to detect unusual behavior or recognize faces for security purposes.
This technology is widely used in airports and hotel check-ins to recognize passengers and guests respectively.
2. Autonomous Cars: Autonomous cars are becoming more common and are considered an important example of artificial intelligence. They use sensors, cameras, and machine learning algorithms to detect obstacles, plan routes, and change vehicle speed based on external factors.
3. Robotics: Another important implementation of AI is robotics. Robots can use machine learning algorithms to learn how to perform various tasks, such as assembling products or exploring dangerous environments. They can also be designed to react to voice or physical instructions.
They are used in shopping malls to help customers and in factories to help with daily operations. Furthermore, you can also hire AI developers to develop AI-powered robots for your businesses. Apart from these, AI-powered robots are also used in other industries such as the military, healthcare, tourism, and more.
4. Voice Assistants: Artificial intelligence is used by virtual voice assistants like Siri, Alexa, and Google Home to understand natural language commands and respond appropriately. Natural Language Processing (NLP) is used by these voice assistants to understand user commands and respond with pertinent information.
5. Image Recognition: Image recognition is a type of artificial intelligence (AI) application that uses neural networks as a way to recognize objects in an image or video frame. It can be used in real time to identify objects, emotions, and even gestures.
The AI and machine learning examples are quite similar and confusing. Both look similar at first glance, but in reality, they are different.
In fact, machine learning is a subset of artificial intelligence. To explain this more clearly, we will differentiate between AI and machine learning.
Machine Learning s Artificial Intelligence: the key differences!
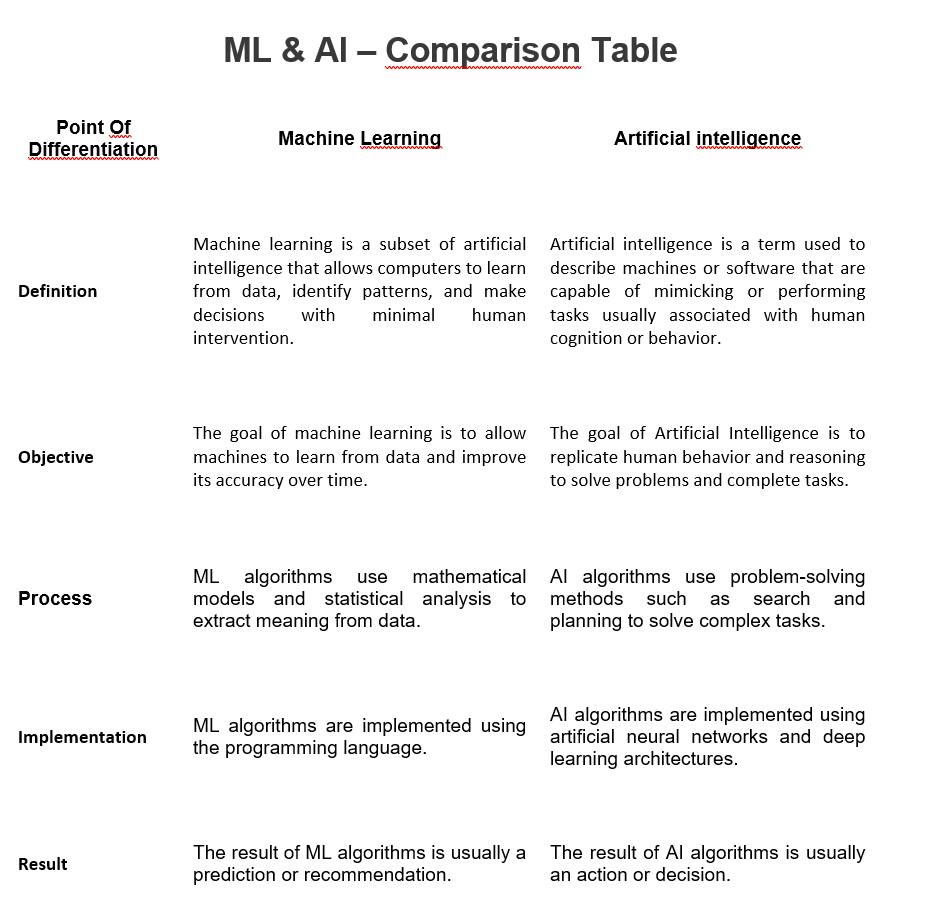
Machine learning (ML) and artificial intelligence (AI) are two related but different concepts. While both can be used to build powerful computing solutions, they have some important differences.
1. Approach:
One of the main differences between ML and AI is their approach. Machine learning focuses on developing systems that can learn from data and make predictions about future outcomes. This requires algorithms that can process large amounts of data, identify patterns, and generate insights from them.
AI, on the other hand, involves creating systems that can think, reason, and make decisions on their own. In this sense, AI systems have the ability to “think” beyond the data they are given and propose solutions that are more creative and efficient than those derived from ML models.
2. Type of problems they solve:
Another difference between ML and AI is the types of problems they solve. ML models are typically used to solve predictive problems, such as predicting stock prices or detecting fraud.
However, AI can be used to solve more complex problems such as natural language processing and computer vision tasks.
3. Computing power consumption:
Finally, ML models tend to require less computing power than AI algorithms. This makes ML models more suitable for applications where power consumption is important, such as mobile devices or IoT devices.
In simple words, machine learning and artificial intelligence are related but different fields. Both AI and ML can be used to create powerful computing solutions, but they have different approaches and types of problems they solve and require different levels of computing power.
Conclusion
Machine learning and artificial intelligence are two different concepts that have different strengths and weaknesses. ML focuses on developing algorithms and models to automate data-driven decisions.
On the other hand, AI emphasizes the development of self-learning machines that can interact with the environment to identify patterns, solve problems, and make decisions.
Both are important to businesses, and it’s important to understand the differences between the two to take advantage of their potential benefits. Therefore, it is the right time to get in touch with an AI application development company, equip your business with AI and machine learning and enjoy the benefits of these technologies.
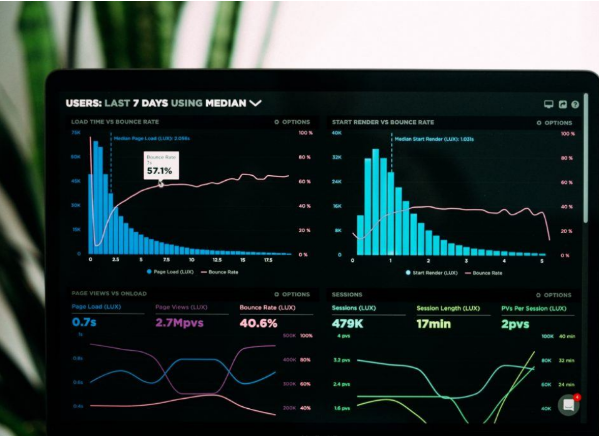
Representing data using graphics such as tables, diagrams, infographics, heat maps, bubble clouds, scatter plots, and mekko charts is called data visualization. These visual displays and information representations help communicate complex data relationships and data-driven insights in a way that makes it easy to understand and inform decisions.
The goal of data visualization is to help identify patterns and trends from large data sets. Data refers to the processing of immersive and interactive visualizations that show new data as it is streamed. There is a huge volume of data available today, and to gain any benefit from that abundance of data, real-time analytics has become extremely necessary for businesses to gain an edge over their competition. Real-time visualizations can be very useful for companies that need to make strategic or on-the-fly decisions.
It is useful for companies that need to deal with risk, both managing it and responding if something goes wrong. And, for those companies that can use these real-time visualizations to take advantage of emerging opportunities before someone else does. Real-time visualizations work best when input-based action needs to be taken immediately by providing context to decision makers.
Business benefits of data visualization:
Information processing: With a constant stream of data being generated in real time, it is impossible to process and make sense of it just by looking at it. Visualization helps make sense of the clutter of numbers and text in a better way. It is also easier to absorb and interpret data when it is presented visually.
Relevant insights: Data visualization provides relevant insights by connecting and showing patterns of how different data sets are connected. This can help easily identify and extract trends and patterns that might not otherwise be visible from the raw data. This is especially important when streaming data is presented and trends can be forecast using real-time visualizations.
In financial trading systems, such real-time data visualizations can show real-time ROI, profit and loss and help companies make immediate decisions.
Business operations: Data visualizations give businesses insight overview of the current relationship between various sections and operations of the business. help in the decision-making process and in the management of critical business metrics. Can Help review and analyze areas for improvement.
Decision making: The pattern becomes clearer with data visualization, facilitating faster decision making. Since there is a synchronization between real-time data and its visualization, companies can make quick decisions that can significantly affect the organization.
Customer Analytics: Real-time data visualization helps analyze customer data to understand business trend. It can reveal information about the understanding and knowledge of the target audience, their preferences and more. Such insights can be helpful in designing strategies that can address customer requirements.
Save time: It is easier to understand, process and make decisions based on graphically represented data instead of going through tons of reports with raw data and generate reports on time. Real-time data visualizations help save time by categorizing and displaying trends and patterns in real time.
Data Interaction: Data visualization helps group and categorize data and encourages employees to spend time on data interaction through data visualization. This leads to better ideas and helps in problem solving. Help design and create actionable business solutions.
Real-time data visualization provides additional context for decision makers who need to respond immediately when faced with risk, and for businesses that need to make quick decisions before an opportunity is missed.
Some of the use cases for real-time data visualizations are:
Conclusion
Data is the key to decision making in any business. Helping the decision-making process by actively rendering real-time data using different real-time rendering and visualization methods can give the business a winning competitive advantage.
WHAT IS DATA LITERACY?
Data literacy is the ability to read, write, and communicate data in context, including an understanding of data sources and constructs, applied analytical methods and techniques, and the ability to describe the application use case and resulting value.
STEP 1: ESTABLISH A BASELINE USING REGISTRATION DATA
Collect log data from your BI tools to compare current adoption and usage rates.
STEP 2: IDENTIFY GROUPS THAT DO NOT USE DATA
Using consolidated log data, identify groups and users with the lowest level of engagement.
STEP 3: EVALUATE DATA LITERATURE
Conduct a data literacy assessment. Identifies unique needs of groups with different skill levels.
STEP 4: IDENTIFY DATA CHAMPIONS
Identify highly qualified power users and departments. Recruit data champions.
STEP #5: CREATE EDUCATIONAL RESOURCES
Interview champions, record videos on best practices, create use cases, tips and tricks that will help educate other groups.
STEP #6: LAUNCH AN EDUCATIONAL CAMPAIGN
Teach and distribute educational resources throughout the organization.
STEP #7: MEASURE PROGRESS: RUN AND REPEAT
Measure changes and adoptions on business performance. Take another skills assessment.
Dongarra’s algorithms and software fueled the growth of high-performance computing and had a significant impact on many areas of computer science, from AI to computer graphics.

New York, NY, March 30, 2022 – ACM, the Association for Computing Machinery, today named Jack J. Dongarra the winner of the ACM A.M. Turing 2021 for his pioneering contributions to numerical algorithms and libraries that enabled high-performance computing software to keep pace with exponential improvements in hardware for more than four decades. Dongarra is Distinguished Professor of Computer Science in the Department of Electrical and Computer Engineering at the University of Tennessee. He is also a member of the Oak Ridge National Laboratory and the University of Manchester.
The ACM A.M. Turing, often referred to as the “Nobel Prize in Computing,” is endowed with a million dollars and is financially supported by Google, Inc. It is named after Alan M. Turing, the British mathematician who articulated the mathematical foundations and computing limits.
Dongarra has led the world in high-performance computing through his contributions to efficient numerical algorithms for linear algebra operations, programming mechanisms for parallel computing, and performance evaluation tools. For nearly forty years, Moore’s Law produced exponential growth in hardware performance. During that same time, while most software couldn’t keep up with these hardware advances, high-performance numerical software did, thanks in large part to algorithms, optimization techniques, and software implementations of Dongarra production quality.
These contributions established a framework from which scientists and engineers made important discoveries and game-changing innovations in areas such as big data analytics, health, renewable energy, weather forecasting, genomics, and economics, to name a few. name a few. Dongarra’s work also helped facilitate advances in computer architecture and supported revolutions in computer graphics and deep learning.
Dongarra’s major contribution was the creation of open source software libraries and standards that employ linear algebra as an intermediate language that can be used by a wide variety of applications. These libraries have been written for single processors, parallel computers, multicore nodes, and multiple GPUs per node. The Dongarra libraries also introduced many important innovations, such as autotuning, mixed-precision arithmetic, and batch calculations.
As the leading ambassador for high-performance computing, Dongarra was tasked with convincing hardware vendors to optimize these methods and software developers to use his open source libraries in their work. Ultimately, these efforts resulted in linear algebra-based software libraries achieving near-universal adoption for high-performance engineering and scientific computing on machines ranging from laptops to the world’s fastest supercomputers. These libraries were essential to the growth of the field, allowing increasingly powerful computers to solve difficult computational problems.
“Today’s fastest supercomputers grab media headlines and pique public interest by performing mind-boggling feats of a quadrillion calculations in a second,” explains ACM President Gabriele Kotsis. “But beyond the understandable interest in breaking new records, high-performance computing has been an important tool of scientific discovery. High-performance computing innovations have also spread to many different areas of computing and have made advance our whole field”. Jack Dongarra played a critical role in directing the successful trajectory of this field. His pioneering work dates back to 1979 and he remains one of the most outstanding and committed leaders in the HPC community. His career arguably exemplifies the Turing Award’s recognition of “great contributions of lasting importance.”
“Jack Dongarra’s work has fundamentally changed and advanced scientific computing,” said Jeff Dean, Google Senior Fellow and SVP of Google Research and Google Health. “His profound and important work at the core of the world’s most widely used numerical libraries underlies all areas of scientific computing, helping to advance everything from drug discovery to weather prediction to aerospace engineering and dozens of other applications.” other fields, and his deep focus on characterizing the performance of a wide range of computers has led to major advances in computer architectures that are well suited to numerical computations.”
Dongarra will formally receive the ACM A.M. Turing at the ACM Annual Awards Banquet, to be held this year on Saturday, June 11 at the Palace Hotel in San Francisco
SELECTED TECHNICAL CONTRIBUTIONS
For over four decades Dongarra has been the main implementer or researcher of many libraries such as LINPACK, BLAS, LAPACK, ScaLAPACK, PLASMA, MAGMA and SLATE. These libraries have been written for single processors, parallel computers, multicore nodes, and multiple GPUs per node. Its software libraries are used almost universally for high-performance engineering and scientific computing on machines ranging from laptops to the world’s fastest supercomputers.
These libraries incorporate numerous far-reaching technical innovations, such as: Autotuning: through its ATLAS project, awarded at the 2016 Supercomputing Conference, Dongarra pioneered the automatic search for algorithmic parameters that produce linear algebra kernels of near-optimal efficiency , often exceeding the codes supplied by the providers.
Mixed-Precision Arithmetic: In his 2006 Supercomputing Conference paper, “Exploiting the Performance of 32-bit Floating Point Arithmetic in Obtaining 64-bit Accuracy,” Dongarra pioneered the exploitation of the multiple precisions of floating-point arithmetic to deliver accurate solutions faster. This work has become a building block in machine learning applications, as recently demonstrated in the HPL-AI benchmark, which has achieved unprecedented levels of performance on the world’s best supercomputers.
Batch Calculations: Dongarra pioneered the paradigm of dividing large dense matrix computations, which are commonly used in simulations, modeling, and data analysis, into many smaller task computations into blocks that can be computed independently and concurrently. Building on his 2016 paper, “Performance, design, and autotuning of batched GEMM for GPUs,” Dongarra led the development of the Batched BLAS standard for these types of calculations, and they also appear in the MAGMA and SLATE software libraries.
Dongarra has collaborated internationally with many people on the above efforts, always in the role of driver of innovation, continually developing new techniques to maximize performance and portability, while maintaining numerically reliable results using the most advanced techniques. Other examples of its leadership are the Message Passing Interface (MPI), the de facto standard for portable message passing in parallel computing architectures, and the Performance API (PAPI), which provides an interface that enables collection and synthesis of the yield of the components of a heterogeneous system. The standards he helped create, such as MPI, the LINPACK Benchmark, and the Top500 list of supercomputers, support computational tasks ranging from weather prediction to climate change to data analysis from large-scale physics experiments.
biographical background
Jack J. Dongarra is a Distinguished Professor at the University of Tennessee and a Distinguished Member of the Research Staff at Oak Ridge National Laboratory since 1989. He has also been a Turing Scholar at the University of Manchester, UK, since 2007. Dongarra has a BA in Mathematics from Chicago State University, received a Master’s degree in Computer Science from the Illinois Institute of Technology and a Ph.D. in Applied Mathematics from the University of New Mexico.
Dongarra has received, among others, the IEEE Computer Pioneer Award, the SIAM/ACM Award in Computational Science and Engineering, and the ACM/IEEE Ken Kennedy Award. He is a member of the ACM, the Institute of Electrical and Electronics Engineers (IEEE), the Society for Industrial and Applied Mathematics (SIAM), the American Association for the Advancement of Science (AAAS), the International Supercomputing Conference (ISC), and the International Institute of Engineering and Technology (IETI). He is a member of the National Academy of Engineering and a Foreign Fellow of the British Royal Society.
About the A.M. ACM Turing
The AM Award Turing is named after Alan M. Turing, the British mathematician who articulated the mathematical foundations and limits of computer science, and who was a key contributor to the Allied cryptanalysis of the Enigma key during World War II. Since its inception in 1966, the Turing Award has honored computer scientists and engineers who created the systems and underlying theoretical foundations that have powered the information technology industry.
About MCA
ACM, the Association for Computing Machinery, is the world’s largest computer science and education society, uniting educators, researchers, and practitioners to inspire dialogue, share resources, and address challenges in the field. ACM strengthens the collective voice of the computing profession through strong leadership, promotion of the highest standards, and recognition of technical excellence. The ACM supports the professional growth of its members by offering opportunities for lifelong learning, career development, and professional networking.

Science seeks the basic laws of nature. Mathematics seeks new theorems based on old ones. Engineering builds systems to solve human needs. The three disciplines are interdependent but distinct. It is very rare for one person to simultaneously make fundamental contributions to all three, but Claude Shannon was a rare person.
Despite being the subject of the recent documentary The Bit Player – and his research work and philosophy having inspired my own career – Shannon is not exactly a household name. He never won a Nobel Prize and was not a celebrity like Albert Einstein or Richard Feynman, neither before nor after his death in 2001. But more than 70 years ago, in a single groundbreaking paper, he laid the foundation for the entire communication infrastructure underlying the modern information age.
Shannon was born in Gaylord, Michigan, in 1916, the son of a local businessman and a teacher. After receiving bachelor’s degrees in electrical engineering and mathematics from the University of Michigan, he wrote a master’s thesis at the Massachusetts Institute of Technology that applied a mathematical discipline called Boolean algebra to the analysis and synthesis of switching circuits. It was a transformative work, turning circuit design from an art to a science, and is now considered to be the starting point of digital circuit design.
Next, Shannon set her sights on an even bigger goal: communication.
Claude Shannon wrote a master’s thesis that launched digital circuit design, and a decade later he wrote his seminal paper on information theory, “A Mathematical Theory of Communication.”
Communication is one of the most basic human needs. From smoke signals to carrier pigeons to telephones and televisions, humans have always sought ways to communicate further, faster and more reliably. But the engineering of communication systems has always been linked to the source and the specific physical medium. Shannon instead wondered, “Is there a grand unified theory for communication?” In a 1939 letter to his mentor, Vannevar Bush, Shannon outlined some of his early ideas on “the fundamental properties of general systems for the transmission of intelligence.” After working on the problem for a decade, Shannon finally published his masterpiece in 1948: “A Mathematical Theory of Communication.”
The core of his theory is a simple but very general model of communication: A transmitter encodes information into a signal, which is corrupted by noise and decoded by the receiver. Despite its simplicity, Shannon’s model incorporates two key ideas: isolate the sources of information and noise from the communication system to be designed, and model both sources probabilistically. He imagined that the information source generated one of many possible messages to communicate, each of which had a certain probability. Probabilistic noise added more randomness for the receiver to unravel.
Before Shannon, the problem of communication was seen primarily as a problem of deterministic signal reconstruction: how to transform a received signal, distorted by the physical medium, to reconstruct the original as accurately as possible. Shannon’s genius lies in his observation that the key to communication is uncertainty. After all, if you knew in advance what I was going to tell you in this column, what would be the point of writing it?
Schematic diagram of Shannon’s communication model, excerpted from his paper.
This single observation moved the communication problem from the physical to the abstract, allowing Shannon to model uncertainty using probability. This was a complete shock to the communication engineers of the time.
In this framework of uncertainty and probability, Shannon set out to systematically determine the fundamental limit of communication. His answer is divided into three parts. The concept of the “bit” of information, used by Shannon as the basic unit of uncertainty, plays a fundamental role in all three. A bit, which is short for “binary digit,” can be either a 1 or a 0, and Shannon’s paper is the first to use the word (although he said mathematician John Tukey used it first in a memo).
First, Shannon devised a formula for the minimum number of bits per second to represent information, a number he called the entropy rate, H. This number quantifies the uncertainty involved in determining which message the source will generate. The lower the entropy rate, the lower the uncertainty, and therefore the easier it is to compress the message into something shorter. For example, texting at a rate of 100 English letters per minute means sending one of 26,100 possible messages each minute, each represented by a sequence of 100 letters. All of these possibilities could be encoded in 470 bits, since 2470 ≈ 26100. If the sequences were equally likely, Shannon’s formula would say that the entropy rate is effectively 470 bits per minute. In reality, some sequences are much more likely than others, and the entropy rate is much lower, allowing for more compression.
Second, he provided a formula for the maximum number of bits per second that can be reliably communicated in the face of noise, which he called the system capacity, C. This is the maximum rate at which the receiver can resolve the uncertainty in the message. , which makes it the communication speed limit.
Finally, he showed that reliable communication of source information versus noise is possible if and only if H < C. Thus, information is like water: If the flow rate is less than the capacity of the pipe, the current happens reliably. Although it is a theory of communication, it is at the same time a theory of how information is produced and transferred: an information theory. That is why Shannon is considered today "the father of information theory". His theorems led to some counterintuitive conclusions. Suppose you are talking in a very noisy place. What's the best way to make sure your message gets through? Maybe repeat it many times? That's certainly anyone's first instinct in a noisy restaurant, but it turns out it's not very effective. Surely the more times you repeat yourself, the more reliable the communication will be. But you've sacrificed speed for reliability. Shannon showed us that we can do much better. Repeating a message is an example of using a code to convey a message, and by using different and more sophisticated codes, you can communicate quickly - up to the speed limit, C - while maintaining any degree of reliability. Another unexpected conclusion that emerges from Shannon's theory is that, whatever the nature of the information (a Shakespeare sonnet, a recording of Beethoven's Fifth Symphony, or a Kurosawa film), it is always more efficient to encode it into bits. before transmitting it. Thus, in a radio system, for example, although both the initial sound and the electromagnetic signal sent through the air are analog waveforms, Shannon's theorems imply that it is optimal to first digitize the sound wave into bits, and then map those bits in the electromagnetic wave. This surprising result is the cornerstone of the modern digital information age, in which the bit reigns as the universal currency of information. Shannon also had a playful side, which she often brought to her work. Here, he poses with a maze he built for an electronic mouse, named Theseus. Shannon's general theory of communication is so natural that it's as if he discovered the communication laws of the universe, instead of inventing them. His theory is as fundamental as the physical laws of nature. In that sense, he was a scientist. Shannon invented new mathematics to describe the laws of communication. He introduced new ideas, such as the entropy rate of a probabilistic model, which have been applied in far-reaching mathematical branches, such as ergodic theory, the study of the long-term behavior of dynamical systems. In that sense, Shannon was a mathematician. But above all, Shannon was an engineer. His theory was motivated by practical engineering problems. And while it was esoteric to engineers of his day, Shannon's theory has become the standard framework on which all modern communication systems are based: optical, submarine, and even interplanetary. Personally, I have been fortunate to be part of a worldwide effort to apply and extend Shannon's theory to wireless communication, increasing communication speeds by two orders of magnitude over multiple generations of standards. In fact, the 5G standard currently being rolled out uses not one, but two proven codes of practice to reach the Shannon speed limit. Although Shannon died in 2001, her legacy lives on in the technology that makes up our modern world and in the devices she created, like this remote-controlled bus. Shannon discovered the basis for all this more than 70 years ago. How did he do it? Relentlessly focusing on the essential feature of a problem and ignoring all other aspects. The simplicity of his communication model is a good illustration of this style. He also knew how to focus on what is possible, rather than what is immediately practical. Shannon's work illustrates the true role of high-level science. When I started college, my advisor told me that the best job was to prune the tree of knowledge, instead of growing it. So I didn't know what to make of this message; I always thought my job as a researcher was to add my own twigs. But throughout my career, when I had the opportunity to apply this philosophy in my own work, I began to understand it. When Shannon began studying communication, engineers already had a large collection of techniques. It was his work of unification that pruned all these twigs of knowledge into a single charming and coherent tree, which has borne fruit for generations of scientists, mathematicians, and engineers.
Although the first CIO was hired nearly 20 years ago, many organizations are beginning to realize the value of data and are looking for someone to oversee their data operations.
The data manager role developed as organizations began to realize the value of data.
Capital One hired the first known Chief Data Officer (CDO) in 2002, but until 10 years ago this role was still quite rare. Since then, however, organizations have realized that data is an asset, and many have taken steps to maximize its value, including hiring a data director.
The need for a chief data officer arose because when organizations began the process of getting value from data, it was often disorganized. Organizations therefore needed someone to oversee the sometimes monumental task of bringing together data from disparate sources and turning it into a functional tool to drive the decision-making process.
In the years since, the role has become more common, and the responsibility of the chief data officer is to enable organizations to get the most value from their data.
A NewVantage Partners study published in January 2021 revealed that 76% of what it called blue-chip companies – large corporations such as American Express, Bank of America, Capital One, Cigna, JPMorgan Chase, Liberty Mutual, Mastercard, McDonalds, Visa and Walmart – now have CIOs and / or CIOs, up from 12% in 2012 and 65% in 2020.
But while large companies, and entire industries such as financial services, have been at the forefront of hiring CIOs, others, such as educational organizations, are beginning to recognize the importance of the role and bring CIOs into their ranks. your templates. The same NewVantage Partners survey revealed that only 24.4% of respondents claim to have forged a data culture and 24% say they have built a data-driven organization.
The pandemic, for its part, has revealed the value of data.
Recently, Cindi Howson, director of data strategy at analytics provider ThoughtSpot and host of The Data Chief podcast, took the time to talk about the role of the chief data officer. In an interview, she explains how the feature originated, how it has evolved since, and where it can be headed.
What are the responsibilities of a data director?
Cindi Howson: A data director is a person who, in the first generation, put a company’s data house in order, gathering the data under an umbrella rather than in silos, making sure it was secure. The change, once the company has done that, is to get value from its data. At this point, there is sometimes a bifurcation of roles between the chief data officer and the chief analyst. We even see that some combine these terms to make someone a CDAO [chief data and analytics officer]. But the question is getting business value from the data.
What’s the difference between a CIO and a CIO?
Howson: If we think that the goal of the data is to extract value from it, there should be no difference. I see them as the same thing. This is a maturation of the role: a mature CDO is the chief analyst. That said, there are some organizations where the chief analytics officer is much more concerned with the data science side of organizations, but ultimately the chief analyst should be responsible for organizing the data, safeguarding it, applying it to value. of the business and create data products. If they aren’t, someone else had better do it.
When did the role of CIO first emerge and why?
Howson: Some of the early CIOs were in financial services, some of the credit card companies, and they realized that they were collecting a lot of data, but it was isolated and the IT department controlled and stored it. and captured. But cleaning them and making them usable required a slightly different skill set. That is why the CDO’s reporting lines are also being seen to change over time. The function originally came from IT – and many CDOs still rely on the CIO – but more and more is being seen than the CDO
it depends on the CEO or the chief digital officer.
How common is this feature now?
Howson: It depends on the survey you look at, and some sectors are much more mature. In general, if I look at all the surveys – Bain, Gartner, NewVantage Partners – I would say that two-thirds of data-heavy organizations have a CDO. But there are some large, multi-million dollar companies that do not have a CDO. I have seen that Peloton is hiring its first CDO, and look at its growth in the last year. Last year, it was the first time the CDC said it needed a CDO; your data house is definitely not in order. And now, in recent years, all federal agencies have their own CDO, but if we go back five years ago that did not exist.
Which organizations need a CIO, and which can do without?
Howson: I think every company that wants to be data-driven needs a CDO, but are non-data-driven companies going to survive? If we wonder if a smaller organization needs a CDO, that responsibility may lie with someone who performs a dual role. In a restaurant, it could be the COO, or they could have it outsourced through an agency that provides a virtual CDO. Everyone needs data. They may not have someone with the title of CDO, but they will have someone who has the responsibility of storing the data, protecting it, and then extracting value from it.
You mentioned industries earlier: are there some industries where more data managers are hired than others?
Howson: It almost coincides with the maturity of the industry data and analysis. If you think of financial services and travel, both are data-intensive industries and tend to have data managers. At the other end of the spectrum, sectors that are less mature in terms of data and analytics tend, unfortunately, to be the most important, such as education and health service providers, which are very different from health payers. health services. Insurance payers are more mature, but providers like large hospital systems – the
Mayo Clinic just hired its first CDO, for example – they are not.
What does a CIO allow an organization to do with its data that an organization cannot do without a CIO?
Howson: This is where the CDO is a connector and a contributor. When you think about data capture, it is very isolated. Take a large retail organization as an example. Retail is a very data-rich industry, but you have the sales and marketing departments doing advertising and marketing campaigns, and then you have the supply chain managers, marketers, and people management systems, And all these operating systems are separate. Now, imagine you want to try to figure out how to staff a warehouse or e-commerce delivery versus how to staff physical stores. You’ll have to go through all those silos to find out demand, see where employees are, find out if an announcement needs to be made, and if you do, find out if there is enough product available. You need that data in a common place, and if you didn’t have it, you would never get any visibility, be it a 360-degree view of customers, supply chain analysis, or workforce analysis.
Are there still obstacles that CIOs have to overcome in their roles, or are CIOs already accepted in some parts of the organizational hierarchy?
Howson: Being a CDO is both the best and the worst job. It is the best job because the world has realized the absolute importance of data for our society and for all companies. Some forward-thinking people have realized this in recent years, but the pandemic, from a business operations standpoint to a healthcare standpoint, has thrown data to center stage. You cannot turn on the television or read a newspaper where data is not discussed in some context. This is good news for CDOs.
The bad news is that it is one of the hardest jobs. You have to know the technology, there are great risks in the implications, and you have to know the business. The company pushes you to do more, faster, and asks CDOs to break down barriers, innovate and take risks. But the IT department says, “Wow, this is dangerous,” so you get pressure on them from both sides, and I think CDOs get exhausted and crushed, so it’s a very rotating role.
What is the landscape of CIOs? Will it become as common a role as CFO or another management role?Howson: If you are a digital native organization, will you really have a CDO role? For example, I just had the Director of Algorithms as a guest on my podcast, which is a preview of the Director of Analytics at Daily Harvest. They do not have a formal CDO. You need data to create the algorithms. It’s just part of the process, and maybe your data house was in order from scratch instead of having it built in on-premises transactional systems. So it really becomes a data product. If you think about moving from data to information, it is something that is taken for granted, whereas in the predigital world it was much more process oriented.
